Null Hypothesis: There is no linear relationship between free lunches and crime rates.
Alternative Hypothesis: There is no linear relationship between free lunches and crime rates.
Y= 21.819+1.685x
79.7=21.819+1.685x x= 34.4%
At a .005 significance level, the null hypothesis is reject, stating that there is a relationship between free lunches and crime rates. However, the R square value is .173, meaning that 17.3% of the time, free lunches explain the crime rates. Meaning that there is a weak significant correlation between crimes rates and free lunches. Although this output can be used to help explain the relationship between the two variables, its lack of a strong R square value means that the analyst of the data should be wary of making solid correlations from this data.
 |
| Figure 1. Linear Regression analysis between free lunches and crime rates. |
Introduction:
For this lab the focus was the University of Wisconsin System. The class was asked to analyze two schools, Eau Claire and another one, to see how the demographics vary across the state. Only the residents from Wisconsin are figured into these calculations. From comparing two different schools, it can be determined if the dynamics across the state vary from school to school.
Methods:
The null and alternative hypotheses are as follows:
Null: There is no significant linear relationship between the two variables.
Alternative: This is a significant linear relationship between the two variables.
From here the excel document was exported to ArcMap and then used in a choropleth map for visualization of the output.
Results:
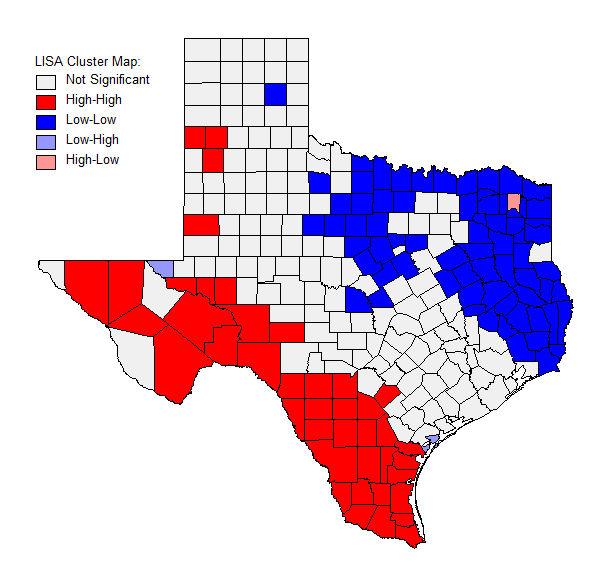
The figure and map below (figures 2 and 3) show that the relationship between Eau Claire Enrollment vs. Percentage of County with a Bachelor's Degree are significant. However, according to the R square value of .121, the relationship is very weak, meaning that one should not rely on the relationship to be true. According to the map, Eau Claire county is the highest valued county in the state.
 |
| Figure 2. Eau Claire enrollment and Percent Bachelor's Degree |
 |
| Figure 3. Map of Eau Claire Enrollment vs % of County with a Bachelor's Degree. |
The figure and map below (figures 4 and 5) show that the relationship between Eau Claire Enrollment and County vs. Population Distance are significant. In the map there are clearly defined areas in which the enrollment is high across the state. These include highly populated regions like Green Bay, as well as counties such as Marathon, Dane, and Waukesha.
 |
| Figure 4. Eau Claire enrollment and distance to Eau Claire. |
 |
| Figure 5. Map of Eau Claire Enrollment vs County Population and Distance. |
 |
| Figure 6. Stevens Point enrollment and Percent Bachelor's Degree |
 |
| Figure 7. Map of Stevens Point enrollment vs % of County with a Bachelor's Degree |
 |
| Figure 8. Stevens Point enrollment and median household income |
 |
| Figure 9. Map of Stevens Point Enrollment vs Median Household Income |
The figure and map below (figures 10 and 11) show that the relationship between Stevens Point Enrollment vs. County and Population Distance are significant. The R Square value at .801 is very high, meaning that the relationship between the two variables is quite reliable.
 |
| Figure 10. Stevens Point Enrollment and distance to Stevens Point. |
 |
| Figure 11. Map of Stevens Point Enrollment vs County Population and Distance |
Something that stood out from the Stevens Point maps was concentration of enrollment in combination with the distance from Stevens Point. This shows that Stevens Point has a large number of students attending their own university. Other than the two main county concentrations of students enrolled in the university, Green Bay is also drawn to attending Stevens Point.
For the variables Eau Claire enrollment and median household income, we fail to reject the null hypothesis, stating that there is no significant linear relationship between Eau Claire enrollment and median household income.
Conclusion:
The fact that all of the Stevens Point linear regressions were significant says that Stevens Point has a certain type of people that go to school there. This generally means that they have similar incomes, and do not come from southern or western Wisconsin.
It would be interesting in a future study to increase the states observed in this study to Minnesota and Illinois. I know that many students that attend Eau Claire are from Minnesota, and being that Stevens Point is closer to Illinois, it would be interesting to see how the linear regression would work with those additional states in consideration.































{kind=link}